Posts in category 'smalltalk'
Persistence in Squeak
Ah, deliciously punny post title. You’ll see, assuming you make it to the end of this thing… don’t worry, I won’t blame you if you don’t.
Over the last week or so, I’ve been working on a little toy project, partly to fill a need I have, and partly to fiddle around with developing a web application in Seaside and Smalltalk, and specifically the Squeak implementation of Smalltalk.
Now, there are many parts needed to build a functional web-based application. Obviously you need a web server to actually serve the application. You need some sort of language to implement the application in. You need a framework in which to actually build that application (okay, sure, back in the days of the wild west, people built their own, but you’d be a fool to do that today given the plethora of frameworks available which simplify the web development process). And last but not least, in all probability, you need a data persistence solution.
Of course, the first thing that comes to mind when turning ones thoughts to persistence is a good old fashioned relational database, which has been the cornerstone of data persistence for many a decade now. But when one is working in a deeply object-oriented language like Smalltalk, working with a relational database becomes rather cumbersome due to the rather substantial impedance mismatch between relational and object-oriented data modeling. As a result, we as an industry have turned to tools such as automated object-relational mappers (eg, Hibernate, etc) to try and ease the pain of this mismatch, but in general, the results aren’t what I would call pretty.
Which is why, during my first hack at leveraging a persistence solution for my little Seaside application, I decided to try something entirely different: an object-oriented database called Magma. Unfortunately, it didn’t go too well.
On Magma
Magma is a very interesting project. As a persistence solution, it really aims for the same space occupied by Gemstone/S: to act as a completely transparent persistence solution for object-oriented data models. By that I mean the idea is that you hand Magma an object graph, and it persists it to it’s own custom data format on disk. When you pull it back out, Magma reifies parts of the object graph you’re interested in, and when you modify the graph, Magma spots the changes and reflects them back into the persistent store.
Of course, on the face of it, this seems like absolute magic. You simply work with your objects. When you want to persist a change, you just do something like:
session commit: [ model doStuff ].And voila, everything just, well, works. Of course, persistence is about more than just simple object storage, in that you also need to be able to query the data model, and be able to do so in an efficient manner. To that end, Magma provides a few specialized collection objects, such as the MagmaCollection class, which provide interfaces for applying indexes, querying, sorting, and so forth.
So, on it’s face, Magma looks like a fantastic solution! The transparent persistence model makes it dead easy to manipulate your data model, and you no longer have to jump through all the object-relational modeling hoops that one would normally have to deal with.
But, alas, it’s just not that easy.
Unfortunately, Magma has one serious fault that rules it out for all but the most basic data-driven applications: It’s slow. Additionally, because Magma absolutely requires per-attribute indexes for any collection you want to query, the number of indexes in a data model can grow substantially, particularly in data mining/exploration tools. Worse, Magma steps on a rather nasty performance problem in Squeak whereby large numbers of files in a single directory (as in, thousands) causes the FileDirectory class to bog down… and guess what happens when you create a large number of indexes? That’s right, a lot of files get created in a single directory, and so you get utterly dismal performance when any index is initially opened.
And as if that weren’t enough, in order to really squeeze decent performance out of Magma, you must start tweaking what are called “read strategies”. See, when you start reifying an object graph, you have to make a decision on how deep to go before you stop. After all, if you have a deep tree of objects, unless you plan to traverse that whole tree at some point, it’s a waste of time to load the whole thing all at once. So the “read strategy” dictates at what depth various parts of the object graph are read. But ultimately, what this equates to is deep micromanagement of the database behaviour, and, quite frankly, I have absolutely no interest in that.
Thus, after many days of fighting, I’ve decided to throw out Magma. Which is rather painful, as I already have an object model built up assuming it’s use. Fortunately, the very nature of Magma means you don’t really tailor the object model too tightly to the database, but things do leak through here and there, and the model itself must, to some extent, be designed to facilitate querying, traversals, and so forth. Thus, any movement away from an RDBMS will necessitate rethinking my data model.
A Way Forward?
So what now? Well, I’ve decided to take the hit and switch to a solution based on Glorp, an object-relational mapping system for Smalltalk, and PostgreSQL, that venerable RDBMS. Of course, this will likely come with it’s own issues, first and foremost one of installation…
Unfortunately, while Squeak package management has taken a step forward with Monticello, the management of dependencies between packages, and inconsistencies between platforms (eg, Pharo vs Squeak) means that things are a lot harder for the user than they need to be. In this particular case, the original Glorp port is rather old. So the folks developing SqueakDBX have worked to port over the latest version to Squeak, with some success. Unfortunately, their installation script doesn’t appear to work in Pharo. So I had to resort to pulling in their loader classes and then manually executing the installation steps by hand. Tedious, to say the least.
But, on the bright side, I have a Pharo image that seems to have a functional Postgres client and Glorp install, so I can start fiddling with those tools to see if they can meet my needs.
Which brings me back to the double entendre. Because returning to the Squeak world has reminded me of one thing: Occasionally the tools get in your way as much as they clear it out for you, and so sometimes you really do need to be incredibly… yes, I’m gonna say it, get ready… here it comes… persistent.
The Seaside Web Framework
While I’m aware that I have, what, maybe two readers of this blog, I thought I might actually start regularly writing a few posts on some of my recent work in the realm of software development. Why? Well, I enjoy writing, and I enjoy… let’s call it “self-gratification”, so posting on my blog seems like a great way to satisfy both of those needs.
So, with all that said, I bring you the kickoff post, covering Seaside.
A Little Introduction
Anyone who’s done any amount of serious web development understands what an absolutely horrible place we, as a development community, find ourselves in. We’re still manually authoring HTML, hacking Javascript, writing AJAX callback hooks by hand, and generally doing all the nasty, gritty, ugly work to make rich web applications possible. Of course, frameworks and abstraction layers have come along to make this a bit easier (Google’s GWT is a great example), but in the end, many of us are still stuck in the dark ages when it comes to web development.
Enter Seaside.
Okay, no, wait, let’s back up one step further.
A Little Pre-Introduction
You all know what Smalltalk is, right? For those not in the know, it’s a nice, high-level, consistent, clean object-oriented programming language that is really the grandfather for many of the programming languages we see today.
Of course, if that were it, we’d probably all be using Smalltalk today. But, alas, the history of Smalltalk is a messy one, sharing many similarities with the Unix battles of old, plagued by myriad, incompatible, expensive implementations that drove away developers to other solutions.
Furthermore, it’s a little strange in at least one respect: rather than code being stored in files, and compiled into binaries, the entire environment, including all your code, is composed into a single “image” from which you must do all you work, including editing, debugging, and so forth. This has great advantages, for example:
- The entire environment is available to you and can be inspected and modified as you desire.
- Deploying an application involves just copying over an image and firing up a VM.
But there’s also major disadvantages:
- You must use the tools provided in the environment (ie, editor, debugger, etc).
- Integration with version control systems isn’t necessarily that great.
- It can be tough to figure out where your code ends and the system begins.
So the picture is certainly mixed. But the sheer power of Smalltalk, the language, and the encompassing environment makes it, at the very least, incredibly intriguing.
As for implementations, for hobbyists, the most commonly used environment is Squeak, or it’s more professional cousin Pharo. I’ve settled on the latter, as it seems to be taking a more professional tack, but it’s really a matter of preference.
By the way, what I’ve said isn’t actually true of GNU Smalltalk, but having never used it, I can’t really speak to it’s viability as a platform. Of course, feel free to take a look at it and let me know what you think!
Where Were We
Oh yeah. Enter Seaside.
So what’s Seaside? Well, it provides an advanced web development framework for Smalltalk that allows the developer to just, you know, get on with it already.
Yeah yeah, I know, you’ve heard that before. So let me illustrate an example for you, and perhaps you’ll see why Seaside excites me so much.
The Example
The program we want to develop is incredibly simple:
- It presents a counter to the user.
- It presents a “decrease” link which lowers the counter.
- It presents an “increase” link which increases the counter.
That’s it. Now imagine, in a traditional web framework, how you would do this. Well, obviously, you need some amount of state, here, in order to track the counter. You could squirrel the value away in a hidden field in a page form (seriously ugly). Or you could assign the user some kind of session ID, and then track the state on the server, using that session ID as a reference (somewhat complicated). Either way, you, the developer, have to focus on how, exactly, that state will be managed.
Now let’s look at how this program would be expressed in Seaside. First, a class declaration:
WAComponent subclass: #Counter instanceVariableNames: 'count' classVariableNames: '' poolDictionaries: '' category: 'Counter'This is a simple class declaration describing a subclass of WAComponent named Counter, and containing an instance variable called ‘count’. Okay, so now we need an initializer:
Counter>>initialize super initialize. count := 0.Again, nothing too special here, we just want to initialize our superclass and our counter. But now comes the meat of the program, and the magic:
Counter>>renderContentOn: html html heading: counter. html anchor callback: [ counter := counter + 1 ]; with: 'increase'. html space. html anchor callback: [ counter := counter - 1 ]; with: 'decrease'.Voila, that’s the entire application, including links and state management.
No, really, that’s it. The whole thing.
So, how does it work? Well, first…
A Bit On Blocks
Like other high-level languages such as Perl, C#, and others, Smalltalk supports the concept of a closure, which is called a block, encapsulating a chunk of code along with it’s lexical scope. That code can then later be invoked at your leisure. For example:
| var block | var := 5. block := [ Transcript show: 'Hello world, my value is '; show: var; cr ].The variable ‘block’ now contains a reference to a closure which we can then invoke later with:
block value.This block remembers everything in it’s lexical scope, so, for example, the variable ‘var’ will retain it’s value, 5, and be emitted on the transcript. This fact, that closures are stateful code objects, is key to the way Seaside works.
Back To The Example
So, in Seaside, you never hand-write HTML. There aren’t even any templating languages. You generate all your HTML with code.
Yes, I know, this is weird, but bear with me.
You see, this has a major advantage. Consider the following piece of code from the example:
html anchor callback: [ counter := counter + 1 ]; with: 'increase'.Of course, this spits out an anchor. Nothing fancy there. But notice how we didn’t specify a URL? That’s weird enough. But notice something else? There’s an argument called ‘callback’, and we’re providing it a block of code. Can you guess what’s happening here?
That’s right. Under the covers, Seaside generates a URL for us. When the link is clicked, Seaside invokes the callback automatically. And because the block remembers the lexical scope, it can fiddle with the counter variable, incrementing it.
So because we let Seaside generate the HTML, suddenly our program is incredibly simple. Under the covers, Seaside manages all our state for us, associating an instance of the Counter object with our browser session. When those links are clicked, the callbacks are invoked in the context of that Counter instance and can manipulate the state of the system. Suddenly we’re no longer hacking HTML, parsing CGI parameters, and all that hideous garbage. We simply write what we want (‘when the user clicks this link, increment the counter’), and Seaside does the rest.
Conclusion
So there you go. A really quick intro to Smalltalk and Seaside. As you can tell, this is incredibly exciting to me. Why? Well, developing web applications has always struck me as incredibly tedious. Rather than just being able to write my damn application, I’m stuck parsing query parameters, managing state, manually handling state transitions, and a whole bunch of other garbage that’s really only peripheral to the actual act of building an application. Seaside, on the other hand, gets rid of all that tedium and lets me focus on the important thing: building a powerful application.
And note, I’ve only just scratched the surface here. Among Seaside’s other powerful features, it has cleanly integrated:
- JQuery
- Prototype
- Scriptaculous
- A general AJAX framework for doing partial page updates
- And probably a whole bunch of other stuff.
Mighty cool if you ask me.
So, all this said, again, the picture isn’t completely rosy. As with all things, there are many issues that Seaside developers must face:
- Myriad persistence solutions that are of mixed quality.
- Code management issues.
- Deployment issues.
- Scaling and performance challenges.
And probably other stuff, too. Which will, of course, be fodder for further posts on this topic.
Running in the Rain - Wetter or Drier?
Well, as anyone living in Edmonton knows, the weather in our area has been, well… rather crappy. Cold, rainy, windy, it feels more like the fall than waning summer. And through it all, I’ve persisted in cycle commuting, mostly because it allows me to justify (excuse) a rather gastronomically decadent lifestyle. Consequently, I’ve found myself caught in more than a few showers over the last few weeks, resulting in much dampness, and, oddly enough, a bit of inspiration.
Now, a favorite show of many folks, myself included, is Mythbusters. They attempt to perform “scientific” experiments to verify or debunk various myths, preconceived notions, and so forth. Now, one of the topics they tackled was: Does moving faster in the rain keep you dry, or get you wetter? Well, in their “experiment”, I seem to recall they found little difference between slow or fast walking, which I found a little surprising, and during a recent bike trip, I found myself pondering how it is they could have found the results they did.
Meanwhile, I’ve also been digging more deeply into the joyous language that is Smalltalk, specifically the Squeak implementation, and a related web application framework called Seaside. However, I’ve been at a loss for a small-scale project to hack up that would allow me to flex my rather atrophed Smalltalk muscles. And so it was that, a couple days ago, while cycling home in the rain, I realized, why not simulate a person walking through a rain storm, and determine whether the Mythbusters results were accurate?
Now, before I get into the details, I should point out this really is pretty non-scientific. I’m sure there are details that I’ve missed which make this simulation completely unrealistic. But, it was fun. :) Now, a bit of explanation about my methodology. First, the simulation is two-dimensional, since I didn’t think the added complexity of doing a full, 3D simulation would generate sufficiently different results. Second, rather than moving my subject through a shower of rain drops at varying speeds, I decided to apply a uniform direction vector to the drops themselves (basically move the drops instead of the subject… the effect is the same, but the implementation is a lot easier). With that said, the experiment is set up as follows (note, these parameters are all configurable, but this is what I chose… they’re entirely arbitrary):
- The rain drop spawn field is 20m by 20m.
- The rain drops are created at a rate of 80 every second, distributed randomly across the top of the spawn field.
- Rain drops fall at the terminal velocity for a typical drop indicated [http://www.grow.arizona.edu/water/raindropvelocity.shtml here] (6.25 m/s).
- The subject is a rectangle approximately 6 feet tall by 6 inches wide.
- The subject’s walking speed varies from 1 to 8 m/s, stepping 0.25 m/s per experiment.
- The subject “walks” a fixed 20m during each experiment.
- Each experiment was repeated 10 times and the results averaged (since rain drops are spawned in random positions).
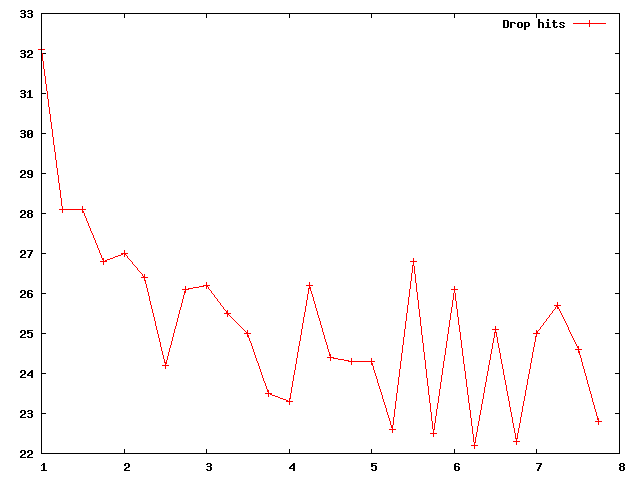
The final tallies can be seen in the graph below:
Granted, it looks a bit noisy, but the general trend appears to indicate that moving faster through a rain storm helps keep you drier! Though, the advantage does seem to level off (it looks like a roughly exponential decay, to me, with the limit at some non-zero value). Remember that, folks… the weather doesn’t look like it’s going to improve. :(
Incidentally, working on this in Squeak has been quite enjoyable. The richness of the class library made many tasks far easier than they would be in other languages, and the ability to fix bugs as I go, and then continue running the code is, to say the least, incredibly cool. And, frankly, I think Smalltalk is the most elegant programming language I’ve ever worked with. :)
Update:
Found an oversight in my simulation, but the above graph now reflects the latest version. In short, I had to make sure the playfield was populated with raindrops before beginning each walk. Otherwise, the subject could complete the walk before a drop ever fell low enough to hit him!
Update 2:
Woo! I win a gold star!